Explanation Of Some Methods
MRFA
Multi-layer Rehearsal Feature Augmentation for Class-Incremental Learning (ICML 2024) [paper] [code]
Accuracy drop after different scales of perturbation

The paper introduces a model named Multi-layer Rehearsal Feature Augmentation (MRFA) for Class-Incremental Learning. Specifically, MRFA enhances the features of rehearsal samples at each layer by performing a gradient ascent step with respect to the features based on the current model. By augmenting the features at the layer level, the margin on the rehearsal samples becomes larger, allowing them to provide more information for refining the decision boundary during incremental learning, thereby alleviating catastrophic forgetting.
EASE
Expandable Subspace Ensemble for Pre-Trained Model-Based Class-Incremental Learning (CVPR 2024) [paper] [code]
Illustration of EASE

The paper introduces a model named ExpAndable Subspace Ensemble (EASE) for Pre-Trained Model-Based Class-Incremental Learning (CIL). The central concept of the EASE model is to train a distinct lightweight adapter module for each new task, creating task-specific subspaces to prevent the overwriting of old knowledge when learning new classes. These adapters expand in a high-dimensional feature space, enabling the model to make joint decisions across multiple subspaces. As data evolves, the expanding subspaces render the old class classifiers incompatible with new-stage spaces. To address this, EASE incorporates a semantic-guided prototype complement strategy that synthesizes new features for old classes without utilizing any instances from the old classes. Extensive experiments demonstrate EASE’s state-of-the-art performance across seven benchmark datasets.
MEMO
A model or 603 exemplars: Towards memory-efficient class-incremental learning (ICLR 2023) [paper] [code]
Illustration of MEMO

The article introduces a model architecture named MEMO (Memory-efficient Expandable MOdel) for addressing Class-Incremental Learning (CIL) problems. The core concept of the MEMO model is to balance the model’s ability to learn new classes and remember old ones under a limited memory budget by efficiently allocating storage space for models and exemplars. Through analyzing the characteristics of different layers within the network, MEMO finds that shallow layers tend to capture generalized features, while deep layers specialize in task-specific features. Leveraging this insight, MEMO extends only the deep layers for new tasks while sharing the shallow layers, thereby saving memory and maintaining diverse feature representations.
PROOF
Learning without Forgetting for Vision-Language Models (arXiv 2023) [paper]
Illustration of PROOF

The article introduces a model named PROOF to address the catastrophic forgetting issue in Class-Incremental Learning (CIL) for Vision-Language Models (VLMs). The PROOF model adapts to new tasks without forgetting previous ones by freezing the pre-trained image and text encoders and appending linear projection layers on top. The image and text embeddings are the sum of all the outputs of the projection layers. To make full use of multi-modal information, the model also incorporates a fusion module that jointly adjusts visual prototypes, textual features, context prompting, and the query instance through a self-attention mechanism, capturing stronger semantic information. PROOF achieves state-of-the-art performance on several benchmark datasets.
ADAM
Revisiting Class-Incremental Learning with Pre-Trained Models: Generalizability and Adaptivity are All You Need (arXiv 2023) [paper] [code]
Illustration of ADAM

The article introduces a model framework called ADAM for Class-Incremental Learning (CIL) tasks. The core idea of ADAM is to combine the generalizability of Pre-Trained Models (PTMs) with the adaptivity in incremental learning, enabling the model to learn new classes without forgetting the old ones.In the first stage of incremental learning, PTMs are fine-tuned using parameter-efficient methods to enhance adaptivity to new class data.The features from the pre-trained model and the adapted model are concatenated to form a new feature representation, retaining the generalizability of PTMs and incorporating adaptive features.Based on feature merging, class prototypes are extracted for classification, helping to maintain a balance between learning new and retaining old classes.Through this structure, the ADAM model achieves effective learning of new classes and retention of old class knowledge during the incremental learning process.
FOSTER
Foster: Feature Boosting and Compression for Class-incremental Learning (ECCV 2022) [paper] [code]
Feature Boosting

The paper introduces a novel two-stage learning paradigm named FOSTER for class-incremental learning, which is inspired by the gradient boosting algorithm to gradually fit the residuals between the target model and the previous ensemble model. The model architecture is designed to dynamically expand new modules to fit the residuals between the target and the output of the original model. The model retains and freezes all parameters of the old model, expands a trainable new feature extractor, and initializes a constrained fully-connected layer to transform the super features into logits. It then removes redundant parameters and feature dimensions through an effective distillation strategy.
BEEF
BEEF: Bi-Compatible Class-Incremental Learning via Energy-Based Expansion and Fusion (ICLR 2023) [paper] [code]
Illustration of BEEF

The paper introduces a model named BEEF (Bi-Compatible Energy-Based Expansion and Fusion) to address the catastrophic forgetting problem that neural networks suffer when learning tasks sequentially. The BEEF model achieves bi-directional compatibility, including backward compatibility and forward compatibility, through two phases:energy-based expansion and fusion. Specifically, the model independently trains new modules during the expansion phase. What’s special is that the model will use a forward prototype(from energy-based generated samples) and a backward prototype(from all the old samples) additionally. Then the model integrates the newly trained modules with the old ones into a unified classifier during the fusion phase by weighting every task’s output. Extensive experiments on datasets such as CIFAR-100, ImageNet-100, and ImageNet-1000 demonstrate that BEEF achieves state-of-the-art performance in both ordinary and challenging class-incremental learning settings.
COIL
Co-Transport for Class-Incremental Learning (ACM MM 2021) [paper] [code]
Illustration of COIL
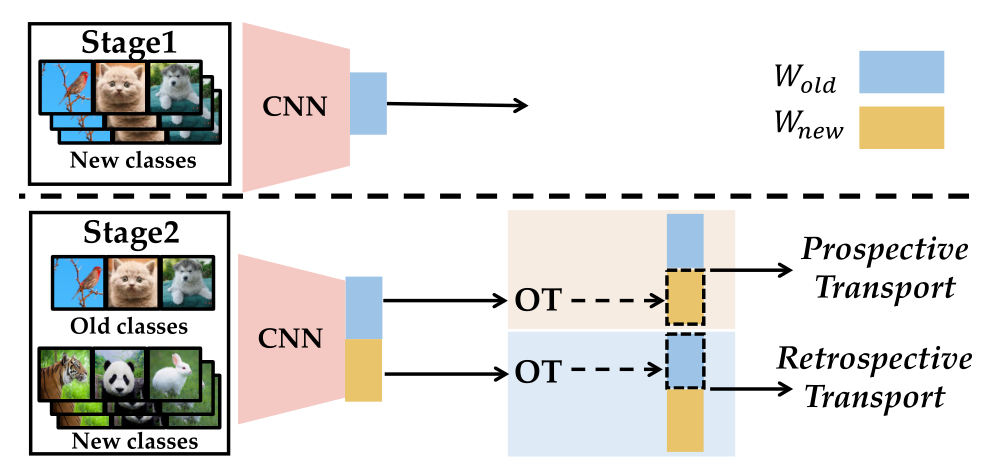
In the image,optimal Transport (OT) refers to a mathematical framework that is used to measure and minimize the cost of transferring mass between two probability distributions.In this paper, OT is creatively applied to model the semantic relationships between classes in an incremental learning scenario.
- The article introduces a model named CO-transport for Class-Incremental Learning (COIL). The model’s core lies in facilitating the correlation between different learning stages through class-wise semantic relationships. Specifically, COIL consists of two main components:
Prospective Transport: This part aims to rapidly adapt the old classifier to new classes by augmenting it with optimally transported knowledge. It accelerates the model’s adaptation to new tasks by transferring knowledge from classifiers of old classes to new ones.
Retrospective Transport: To overcome the forgetting issue, this part retroactively transports new class classifiers back as old ones, helping to preserve old knowledge.
Through these two transport mechanisms, COIL efficiently adapts to new tasks while stably resisting forgetting. Experiments demonstrate COIL’s effectiveness on various benchmark and real-world multimedia datasets.